Cont’d from the previous blog post…
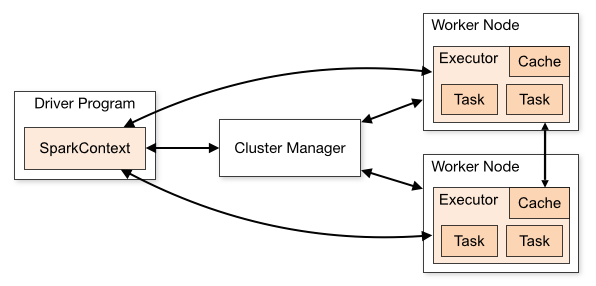
As mentioned earlier, WSO2 DAS embeds Spark, and by default a Spark cluster is created inside a DAS cluster. In this post, we will look at how we could configure the nodes, to get the best out of the DAS analytics cluster.
For more information about how clustering is done in DAS, please refer the DAS Clustering Guide.
DAS Cluster – Explained…
A typical DAS cluster can be depicted as follows.
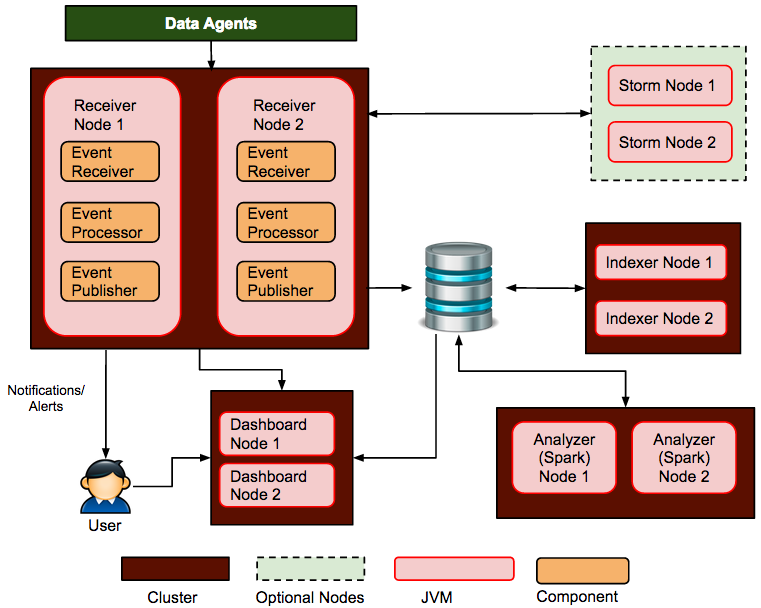
In this setup, the Spark cluster resides in the “Analyzer sub cluster”. It will be responsible for instantiating the masters, workers and the driver application.
The main configurations of the DAS cluster is governed by the <DAS home>/repository/conf/analytics/spark/spark-defaults.conf file. The default content of this file is as follows.
# ------------------------------------------------------ # CARBON RELATED SPARK PROPERTIES # ------------------------------------------------------ carbon.spark.master local carbon.spark.master.count 1 carbon.spark.results.limit 1000 carbon.scheduler.pool carbon-pool # ------------------------------------------------------ # SPARK PROPERTIES # ------------------------------------------------------ # Application Properties spark.app.name CarbonAnalytics spark.driver.cores 1 spark.driver.memory 512m spark.executor.memory 512m # Runtime Environment # Spark UI spark.ui.port 4040 spark.history.ui.port 18080 # Compression and Serialization spark.serializer org.apache.spark.serializer.KryoSerializer spark.kryoserializer.buffer 256k spark.kryoserializer.buffer.max 256m # Execution Behavior # Networking spark.blockManager.port 12000 spark.broadcast.port 12500 spark.driver.port 13000 spark.executor.port 13500 spark.fileserver.port 14000 spark.replClassServer.port 14500 # Scheduling spark.scheduler.mode FAIR # Dynamic Allocation # Security # Encryption # Standalone Cluster Configs spark.deploy.recoveryMode CUSTOM spark.deploy.recoveryMode.factory org.wso2.carbon.analytics.spark.core.deploy.AnalyticsRecoveryModeFactory # Master spark.master.port 7077 spark.master.rest.port 6066 spark.master.webui.port 8081 # Worker spark.worker.cores 1 spark.worker.memory 1g spark.worker.dir work spark.worker.port 11000 spark.worker.webui.port 11500 # Spark Logging # To allow event logging for spark you need to uncomment # the line spark.eventlog.log true and set the directory in which the # logs will be stored. # spark.eventLog.enabled true # spark.eventLog.dir &amp;amp;amp;amp;amp;amp;amp;lt;PATH_FOR_SPARK_EVENT_LOGS&amp;amp;amp;amp;amp;amp;amp;gt;
There are 2 sections
- Carbon related configurations
These are carbon specific properties when running Spark in the Carbon environment and they start with the prefix “carbon.”
- Spark configurations
These are the default properties shipped by Spark. Please refer this for Spark environment variables.
I will explain the uses of these configuration as I explain the setup of a Spark Cluster.
DAS Spark Clustering approach
DAS Spark cluster is controlled by the carbon clustering and a sub-cluster abstraction. This sub-cluster has enabled DAS to create a subset of members in its carbon cluster. These subsets are being used for DAS analytics cluster as well as the indexing cluster.
Default setup
In the vanilla DAS pack, Spark would start in the “local” mode. Refer this.
Single node setup
In the single node setup, the DAS server will instantiate a master, a worker and a spark app all in a single node. To enable this, you would have to enable carbon clustering in axis2.xml file and leave ‘carbon.spark.master local’ as it is.
Multi node setup
This will be an extension to the single node setup. A multi-node setup is used to achieve high availability (HA) in the DAS analytics cluster. In addition to single node setup configs, ‘carbon.spark.master.count’ becomes an important property in this setup. carbon.spark.master.count specifies the number of masters which should be available in the analytic cluster.
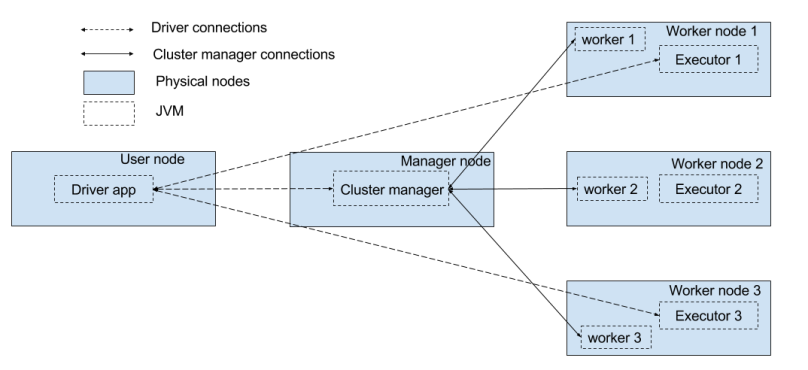
In a multiple master setup, there will be one active master and the rest will be standby. The active master will be responsible for distributing the resources among the executors.
Once the carbon.spark.master.count is reached, each member of the analytics cluster, would start a worker pointing to a list of available masters (both active and standby).
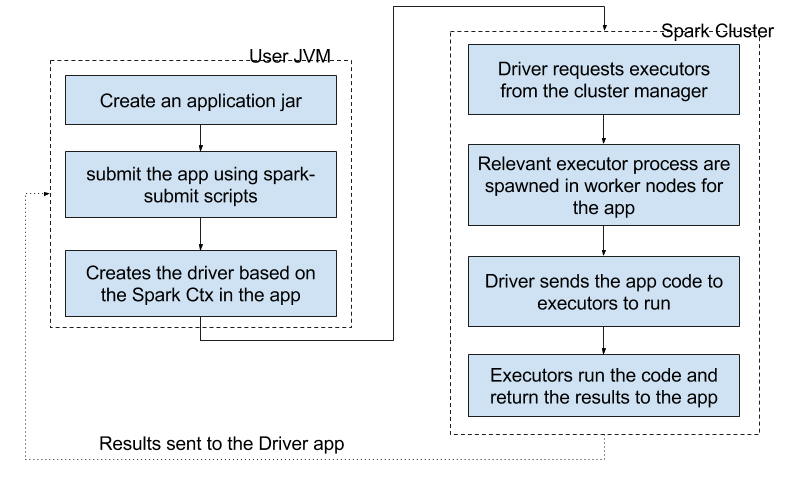
Once the masters and the workers are instantiated, the Spark cluster configuration completes. Then a spark application will be spawned in the analytic cluster leader.
This setup can handle master and/or worker fail overs. Let us talk in detail about this in another blog post.
Resource tuning of DAS analytic nodes
In a DAS production environment, it is important to allocate the resources correctly to each node, in order to achieve optimum performance.
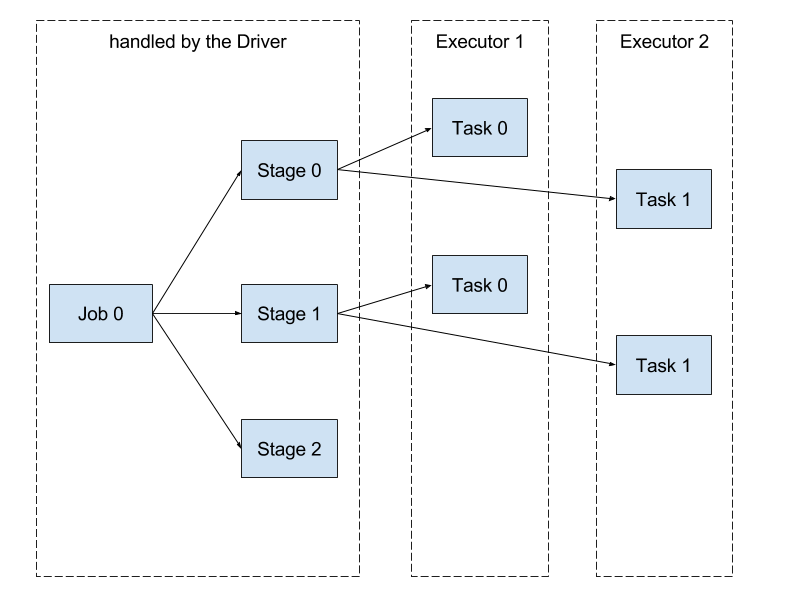
Let us first look at a typical multi node DAS setup, to understand how the resources should be allocated.
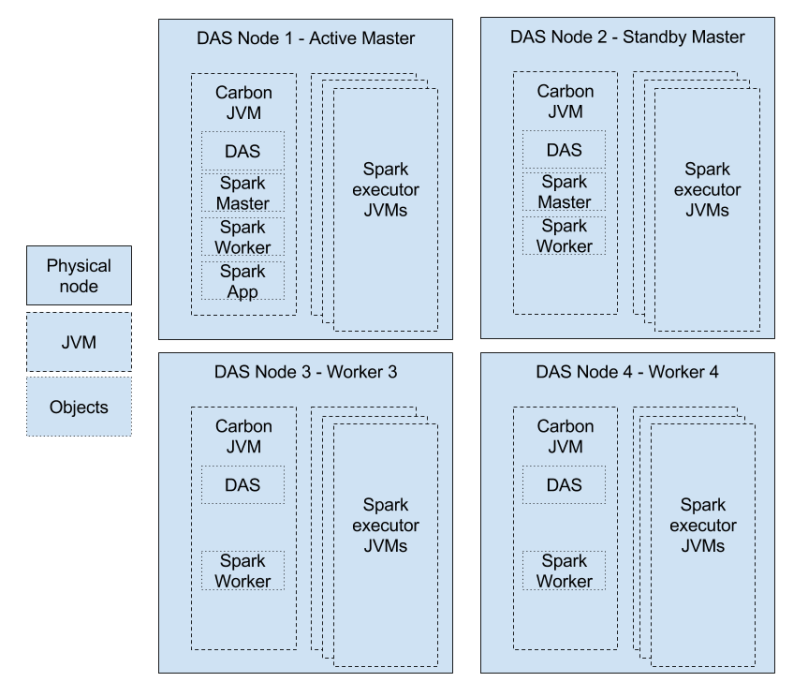
As you could see here, the resources of the cluster need to be distributed among these components depending on the requirement.
Main configuration parameters
There are several important configuration parameters. Resources are mainly revolve around the number of cores available and memory available. (Note that DAS is using the Standalone cluster mode)
| Parameter | Default value | Comment |
|---|---|---|
| Cores | ||
| spark.executor.cores | All the available cores on the worker | The number of cores to use on each executor. Setting this parameter allows an application to run multiple executors on the same worker, provided that there are enough cores on that worker. Otherwise, only one executor per application will run on each worker. |
| spark.cores.max | Int.MAX_VALUE | The maximum amount of CPU cores to request for the application from across the cluster (not from each machine) |
| spark.worker.cores | 1 | The number of cores assigned for a worker. |
| Memory | ||
| spark.worker.memory | 1g | Amount of memory to use per worker, in the same format as JVM memory strings (e.g.512m, 2g). |
| spark.executor.memory | 512m | Amount of memory to use per executor process, in the same format as JVM memory strings (e.g.512m, 2g). |
So, the number of executors in a single worker for the carbon-application can be derived from,
number of executors in a single worker
= FLOOR ( MIN (spark.worker.cores, spark.cores.max) / spark.executor.cores )
Then the amount of memory which should be allocated for a worker should be,
spark.worker.memory ≥ spark.executor.memory × number of executors
Configuration patterns
By setting different values for each of the parameters above, we can have different configuration patterns.
Let’s take an AWS m4.xlarge instance for an example. It has 8 vCPUs and 16 GB memory. If we allocate 4 GB and 4 cores to the OS and the Carbon JVM (by default this only takes 1GB memory), then we can allocate spark.worker.memory = 12g and spark.worker.cores = 4.
Single executor workers
If we do not specify spark.cores.max or spark.executor.cores then, all the available cores will be taken up by one executor.
Executors = min (4,Int.MAX_VALUE)/4 = 1
So, we could allocate all the memory for that executor, i.e. spark.executor.memory=12g
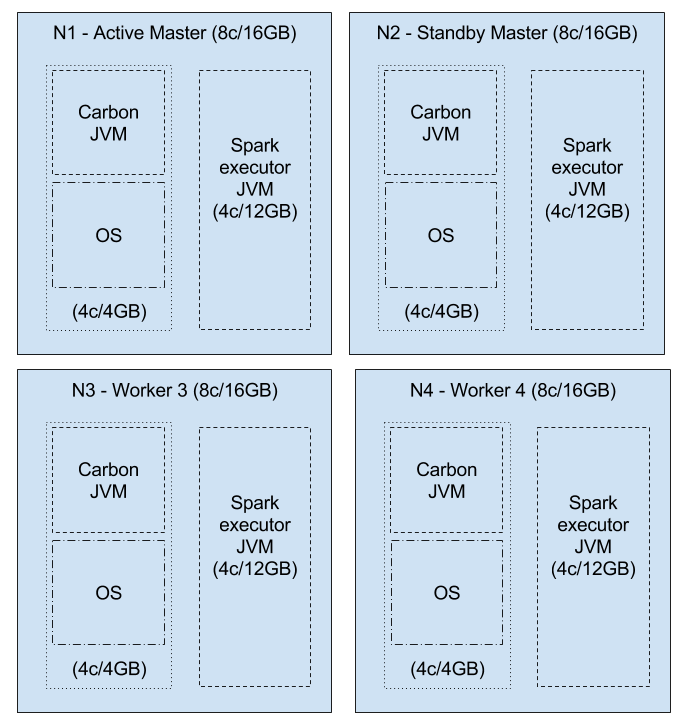
NOTE: Having large amount of memory for a single JVM is not advisable, due to GC performance.
Multiple executor workers
Let’s say, we specify spark.executor.cores = 1
Then executors = min (4, Int.MAX_VALUE) / 1 = 4
Therefore, we could allocate 12GB/4 = 3GB per executor
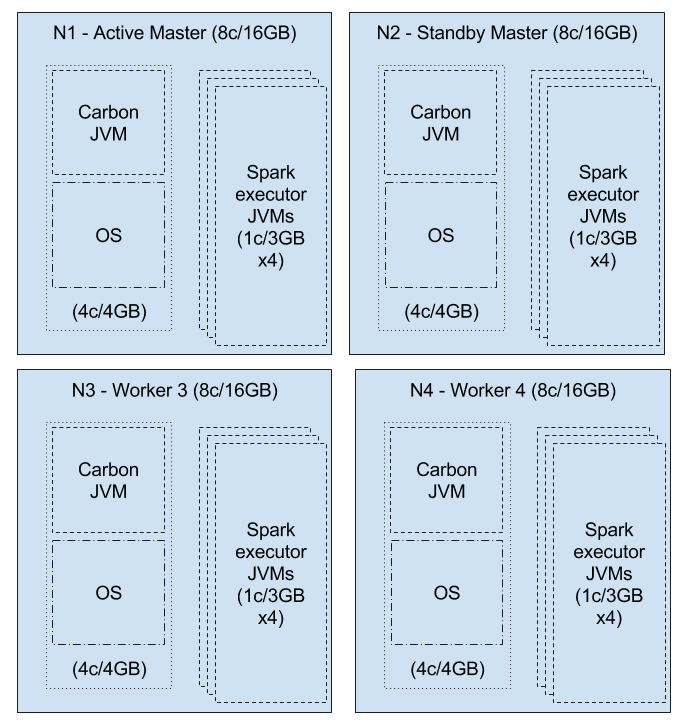
Resource limited workers
We can limit the number of cores used for the carbon application cluster-wide by setting the spark.cores.max value.
Let’s set spark.cores.max = 3 per node x 4 nodes = 12. Then, there is an excess of 4 cores, which can be used by some other application.
Let’s take the above multiple executor setup.
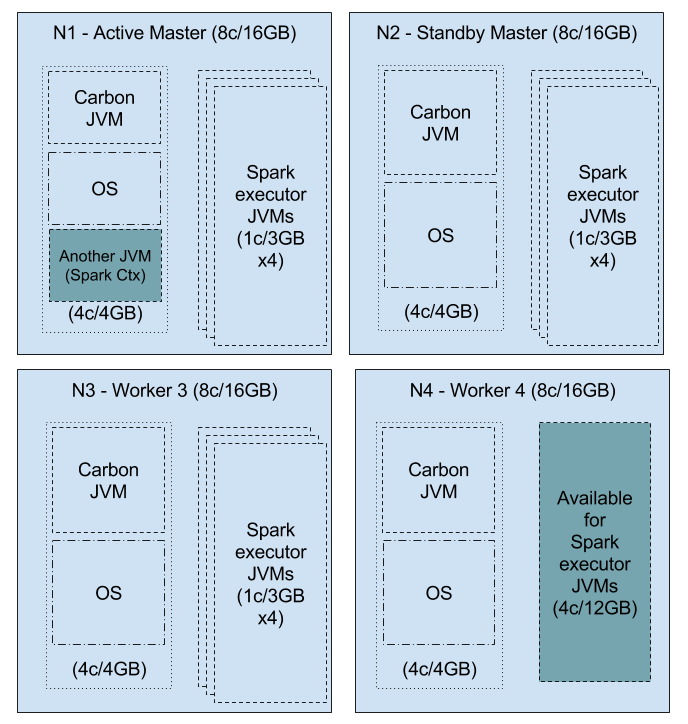
Here, there are is resources for 16 executors with 16 cores and 48GB of memory. With the spark.cores.max = 12 (i.e. 3 x 4), 12 executors will be assigned to the carbon application and the rest of the cores and memory can be assigned for another spark application, i.e. 4 cores and 12 GB will be available in the cluster, which can be used by the application, depending on its preference.
So, as depicted above, depending on the requirement and resources available, you should distribute the cores and memory among the workers.
Cheers